



In this series of two-part articles, the aim is to give an introduction to what fuzzing is and also summarizes points discussed in the Mentorship Session: Fuzzing the Linux Kernel talk by Andrey Konovalov part of the Linux Live Mentorship Series. Summarization I believe is a great way to establish an understanding of the topic. All the images used in this blog post can be found in Author's slide deck as linked here. Since Linux fuzzing might seem like an intimidating topic, its better to break the topic into two-part series with Part 1(this article) covering Fuzzing 101 and Part 2 covering its application and details pertinent to Linux Kernel
Fuzzing Theory
What is fuzzing?
Fuzzing is an automated bug-finding technique where randomized input is fed to the target program to get that target program to crash or perform some undefined behavior(such as infinite loop, memory corruption, etc). These behavior are signs of underlying vulnerabilities that a software might have. The idea of fuzzing comes from Infinite monkey theorem which states that if a monkey is given a typewriter and infinite time, then it can successfully compose Shakespear's work by randomly hitting the keys of the typewriter.
While trying to fuzz any given program(Application, Library, Kernel, Firmware, etc.) we need to ask the following 5 essential questions:
- How do we execute the program?
Easier for UserSpace Programs but difficult for Kernel/Firmware programs
- How do we feed in input?
Standard Input/Output for a program is simple, however accepting input from a USB device is difficult.
- How do we generate the input?
Generating a random input as per the infinite monkey theorem is cumbersome, there should rather be a smart way to generate inputs
- How do we detect crashes?
Detecting userspace program crash is easy however let's say a kernel program corrupts a memory space by out-of-bound operation. In that case, the crash does not happen immediately. So we have to rely on something better than application crashing
- How can we automate the process rather than requiring manual developer effort?
Answers to questions 1, 2, 4 & 5 depend on the program we are fuzzing, however, the answer to question 3 is uniform across different target programs.
How do we generate input?
Thought Experiment: Let's say we have an XML file parser, now how do we generate input for that? The simplest approach would be to just generate random binary data, however, there could be a possibility that the XML file parser accepts inputs only when it started with some tag. In that case, we are wasting many of our possible combinations. Therefore, random binary data works poorly as inputs.
Therefore, there exist three possible ways to generate better inputs:
- a) Structured Aware fuzzing
- b) Coverage Guided fuzzing
- c) Collecting Corpus of Sample Inputs and Mutating Them
a) Structured Aware fuzzing
In this type of fuzzing, we come up with a grammar that describes the input format. For instance in the case of XML instead of generating random bytes we can use random tags which could have been generated had there been some way that could account for an XML grammar. Only then would our input pass the XML tag check.
b) Coverage Guided fuzzing
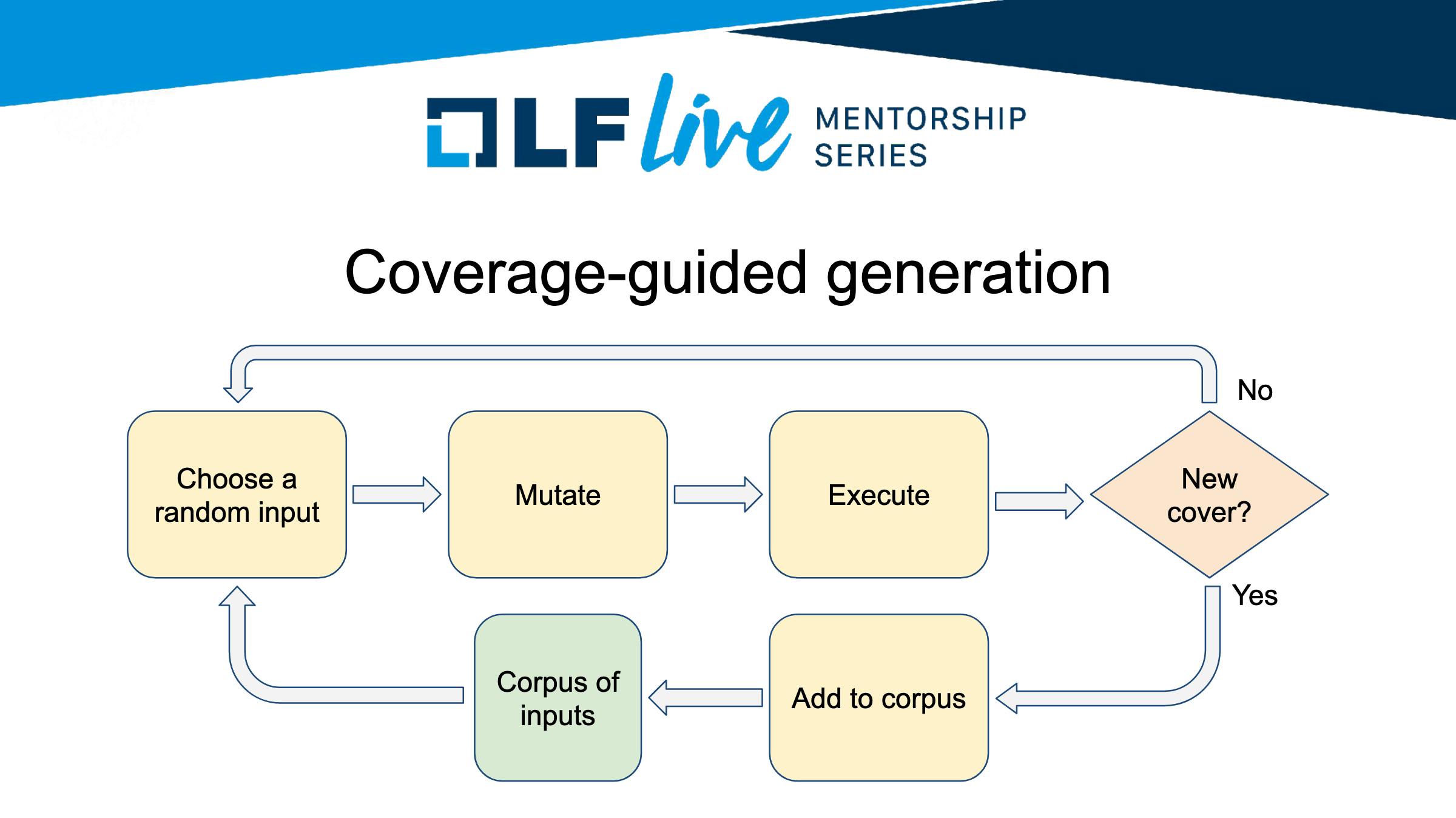 Image fetched from one of speaker's slide
Image fetched from one of speaker's slide
This way we can explore new code instructions, and explore new passes within our program. As mentioned in the diagram "Cover"(short for code coverage) is not the only signal for validating input, other signals include Memory State. For instance, for each new input that we are going to process we are going to be tracking a value of some global variable, and whenever this global variable changes into some new value for our input, we remember that input to be used as possible test input.
Further, we can also combine the Guided approach with Structured Aware inputs approaches and mutate accordingly.
c) Collecting Corpus of Sample Inputs and Mutating Them
For the XML file parser example, we can scrap XML files off the internet. Further, mutating them and feeding them into the program can provide us with more possible input options.
We can even combine the collected corpus with the previous two approaches and parse the sample to mutate with structure awareness.