

Photo by Jay Ruzesky on Unsplash
Fuzzing 101 and Notes on Fuzzing the Linux Kernel Part 2
How can Fuzzing be applied to Linux Kernel Development


In this series of two-part articles, the aim is to give an introduction to what fuzzing is and also summarizes points discussed in the Mentorship Session: Fuzzing the Linux Kernel talk by Andrey Konovalov part of the Linux Live Mentorship Series. Summarization I believe is a great way to establish an understanding of the topic. All the images used in this blog post can be found in Author's slide deck as linked here. Since Linux fuzzing might seem like an intimidating topic, its better to break the topic into two-part series with Part 1 covering Fuzzing 101 and Part 2(this article) covering its application and details pertinent to Linux Kernel
Fuzzing the Linux Kernel
What kind of inputs does the kernel have?
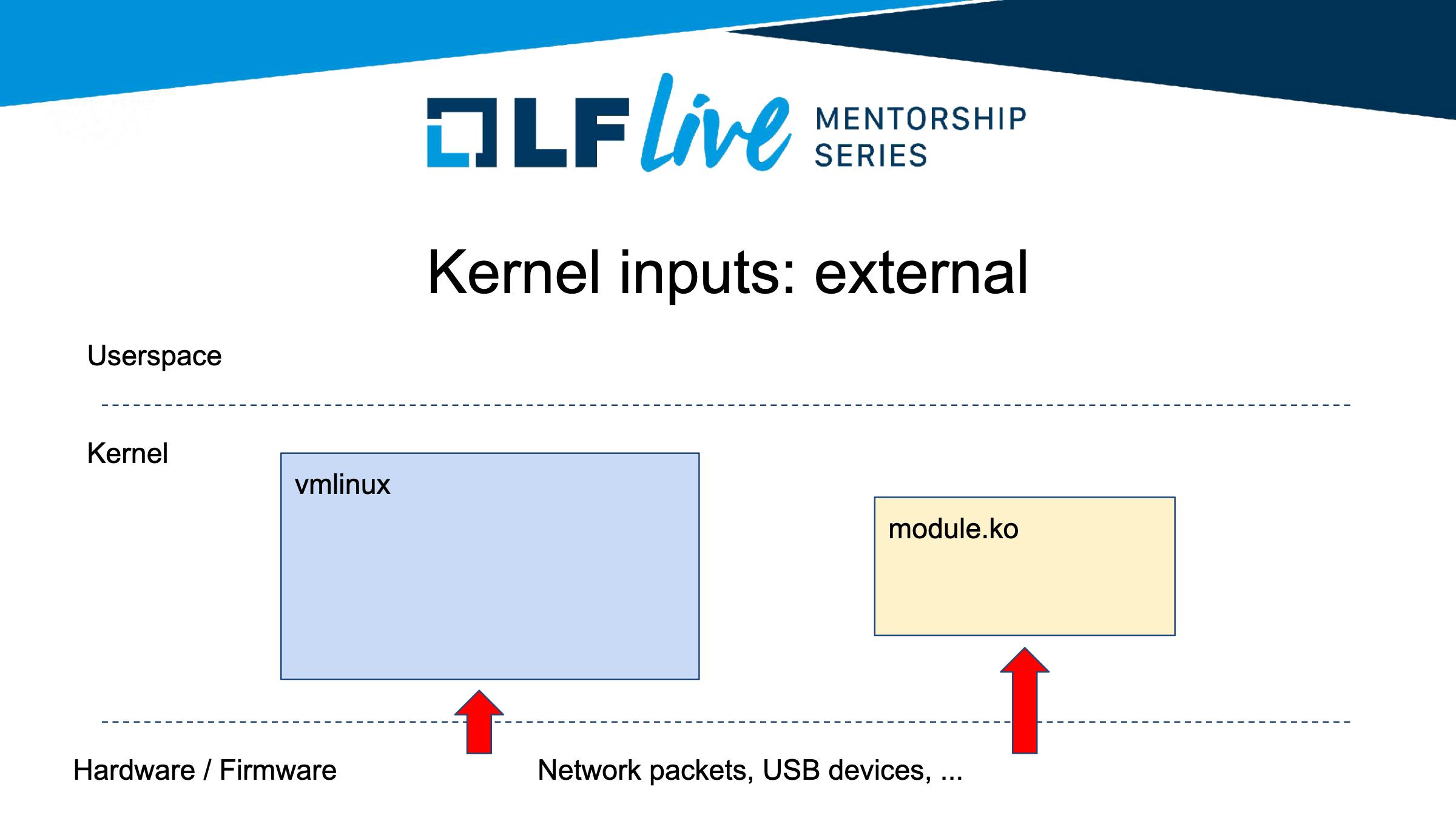 Whenever we have a userspace application running it executes syscalls(System Calls), and the kernel is supposed to be servicing these syscalls. So for fuzzing kernel, we can use these syscalls. However, we can also have some external inputs such as Network Packets, USB Devices, and other buses. In some cases, firmware can also interact with the kernel and send some internal inputs to it.
Whenever we have a userspace application running it executes syscalls(System Calls), and the kernel is supposed to be servicing these syscalls. So for fuzzing kernel, we can use these syscalls. However, we can also have some external inputs such as Network Packets, USB Devices, and other buses. In some cases, firmware can also interact with the kernel and send some internal inputs to it.
What are syscalls?
Syscalls are the programmatic way in which a computer program requests a service from the kernel of the operating system on which it is executed.
For fuzzing the Linux Kernel let's cover the basics by answering the 5 essential questions mentioned in Part 1.
How do we Feed/Inject in input?
If the inputs are generated from hardware we can take a piece of hardware and use it to generate inputs but that scales poorly and doesn't always work. The other two approaches that we can use are either injecting inputs from userspace or using Hypervisors/Emulators. As an example, if we are doing network fuzzing, there is a thing called tuned-up interface. Basically, we set up the dev/tun device properly whenever we are writing data into it, it will be going through the same parsing path in the kernel as if the packets were received externally.
Another approach for injecting input is using a hypervisor, an example would be that for USB we can use QEMU and USBredir which is a protocol for actually transferring USB data from the host to the guest. There is a fuzzer called vUSBf that does exactly that.
How do we generate inputs?
Since one of the ways of communicating kernel is using Kernel Syscalls, Andrey(the speaker) introduces API-aware fuzzing, wherein we pass structured input syscalls sequences as input. Further, for coverage-guided fuzzing, we should be generating /mutating in a structured manner to generate fuzzing input ( Inserting / Removing calls and changing arguments for the call). Syzkaller(probably the most used tool) helps us accomplish API Aware fuzzing(we'll be talking about it in a further section).
One important thing to take into account while creating an API-aware fuzzer is to take care of ways in which we can divert the execution flow. This will be useful for commands such as clone, sigaction, etc.
For other external source syscalls inputs, we would need to evaluate potential strategies. For instance, USB is fully host-driven if we are trying to emulate the USB device, we are not making API calls but instead are responding to them(coming from USB). We are not sure which kind of call is going to arrive next so our fuzzer has to account for that.
How do we execute the program?
Before executing the program we also need to define some kind of metric that could help us with understanding the execution stats of the program. One such metric is Code Coverage.
Code Coverage simply represents how many lines of code are covered through unit tests. To do code coverage guided fuzzing we need some way to collect code coverage and there are three approaches that people generally use:
Compiler Instrumentation-based approach: Compiler Instrumentation-based code coverage is an idea where you are relying on a compiler to insert certain types of callbacks into your code and then from those callbacks collect a trace of execution.
Emulator-based approach: In emulator-based code coverage, let's say we are running kernel in an emulator. The emulator has a loop that executes instructions one by one. So we can just dump out the extraction pointer and get the execution trace.
Hardware-based Tracing approach: In this approach, we start dumping out trace into some physical address space, and inspect that trace afterwards.
The two ways of executing Kernel is to run it over Physical Device or VM/Emulator. The bad thing about physical devices is that they are hard to manage, they are hard to restart, hard to get kernel logs from, and they are hard to debug. Also if we are running fuzzers as root on the device there are chances that our device might get bricked.
Bricked Device: An electronic device such as mobile, router is bricked when due corruption of memory, hardware and firmware they are unable to work any longer.
In terms of scalability it is easier to spawn more VM's than buy more physical devices.
How do we detect crashes?
Some of the tools used for Dynamic program analysis are:
- KASAN: Detects Memory Corruption
- KMSAN: Detects uninitialized memory use for the Linux kernel
- KCSAN: dynamic race-detector for the Linux kernel
- KFENCE: It detects heap out-of-bounds accesses, use-after-free, and invalid-free errors
There are other tools available as well that can be used for static code analysis, some of them are mentioned below:
- Coccinelle
- Smatch
gcc -fanalyzeclang --analyze
Static analysis is known for identifying many False Positive bugs whereas Dynamic Analysis is inclined more toward analyzing True Positive bugs.
For more information on Dynamic Program Analysis checkout out this awesome talk by Dmitry Vyukov
How can we automate the process rather than requiring manual developer effort?
Following are the requirements that need to be fulfilled by any fuzzing automation tool:
Monitoring Kernel logs for crashes
Restarting crashed kernel VMs
Deduplicating Crashes: Similar types of crashes should be grouped together
Generating Reproducers
Reporting Bugs/tracers/fixers
While creating any fuzzers we should aim to accommodate the above-mentioned requirements, lucky for us Syzkaller already covers all of them. Hence, our fuzzer can be built by reusing syzkaller.
Trinity and Syzkaller
Two fuzzers discussed in this lecture used for kernel development are Trinity and Syzkaller
Trinity: It's running an infinite loop and trying to call different syscalls in this loop. It does not generate inputs or series of syscalls. It only tries to generate an infinite sequence of syscalls. But this fuzzer is API aware because it knows about different kinds of syscalls and that some syscalls are supposed to be accepting particular structures. However, it offers no coverage guidance.
Syzkaller: Syzkaller was a great improvement over trinity, it introduced the notion of test case so instead of generating an infinite stream of syscalls it generates finite sequences and executes them. It also includes isolation for running those sequences. This isolation is not perfect because syzkaller still reuses the same kernel to run multiple inputs. But, it tries to use different types of Sandboxes and Namespaces. It is also coverage guided, the moment we have test cases, it can be mutated to execute the larger portion of code.
Further, instead of hardcoding syscalls and their respective structure into their implementation. It provides the language for that and that language is called syzlang.
Finally, Trinity is just a binary, everything else we need to do it on our own. If our VM crashes we have to restart. Whereas in syzkaller we have everything built-in. It also introduces mighty syzbot, which are a few dozen syzkaller instances running in the cloud targeting mostly mainline kernel but some other kernels as well.
To sum up, syzkaller is great at fuzzing API-based interfaces.
Tips about using Syzkaller
- Don't fuzz mainline with a default config(that's already done by syzbot), fuzz a smaller number of syscalls, and even consider fuzz distro kernel maybe bugs are fixed in the mainline kernel but not in the distro kernel.
- Build your fuzzer on top of syzkaller, maybe reuse some components of syzkaller
Fuzzing tips
- Read the code
- Writing a fuzzer based on documentation/spec does not necessarily work too well.
- Instead of relying on documentation read the code, see what kind of input it expects and write a fuzzer based on that.
- Identify the part of the code we want to target
Collecting Coverage with KCOV
- KCOV is a tool for collecting code coverage from Linux Kernel
- Available upstream, and is enabled by CONFIG_KCOV
- Based on compiler instrumentation, when enabled we would need to rebuild the kernel
- Can collect code coverage from both user threads and background threads.
Fast vs Smart Fuzzer
- Fast Fuzzer basically provides more exec per second.
- Smart Fuzzer has better input generation and relevant guidance signal.
Focus on creating a smart fuzzer in the first place.
Final Notes
- Developing a fuzzer is engineering, you have to be good at writing code(besides reading it for review)
- Good Fuzzer finds too many bugs, however, there are many False Positives(like is the case with Static Analysis)